
迪士尼彩乐园为人类 现场直击黄仁勋CES 2025演讲:荒诞的不雅众与超等芯片队长
发布日期:2025-01-08 06:46 点击次数:84

作家|王艺 苏霍伊
裁剪|王博
发自好意思国拉斯维加斯CES 2025现场
《Without Your Shotgun》因循又动感的旋律戛可是止,衣服闪亮的新夹克,英伟达CEO黄仁勋走向CES的舞台中央。
“Are you excited in Las Vegas(你们可爱拉斯维加斯吗)?”“Do you like my jacket(你们可爱我的夹克吗)?”
而在此之前,通盘拉斯维加斯齐在屏息以待,直到黄仁勋掏出了RTX 50系列消耗级显卡(GPU),会场才被掌声与答允声并吞。
这是黄仁勋时隔多年再次来到CES(Consumer Electronics Show,海外消耗类电子家具博览会)发表主题演讲,上一次如故在2019年,他在CES上发布了RTX 20系列显卡。
当地时当前午2点,距离行动开动还有4个小时,就有参会者来到了演讲会场Mandalay Bay Arena。演讲开动前,会场门口依然排起了看不到头的队伍,在东说念主群中,一位不雅众对「甲子光年」辱弄:“这几个小时我已和附近东说念主唠成一又友,再等下去就快成兄弟了。”

黄仁勋演讲会场门口的“长龙”,图片起原:UASC Semi
全全国的媒体也将眼神聚焦在英伟达。
“我主要期待英伟达在芯片、机器东说念主和在汽车方面的新作为。”一位来自日本的电视记者对「甲子光年」说说念。而来自印度报业托拉斯的记者Yashita则暗示,旧年10月英伟达推出印地语AI模子,是以她更孤寒此次新发布会对印度AI产业带来的促进与影响。
这一次,黄仁勋的主题演讲有以下要点内容:
发布史上最快的消耗级显卡RTX 5090;
提议Scaling Law仍在链接,并暗示要创建一个名为Grace Blackwell NVLink72的巨型芯片;
在NIM微行状中新增Nemotron系列模子和用于视频搜索和摘录的AI代理,入局Agentic AI;
发布Nvidia Cosmos全国基础模子平台,以助推Physical AI的发展;
发布东说念主形机器东说念主合成数据蓝图Isaac GR00T Blueprint和新一代智驾芯片Thor;
发布全球最小的个东说念主AI超等想到机Project DIGITS。
FPSolution VC首创合资东说念主、SpaceX前华侨高管Lewis Hong在听了黄仁勋的演讲后作念了一个勇猛的推断:“英伟达接下来也许会平直吃掉通盘‘Magnificent 7’的‘饼’,大概惟一可以跟他们抗衡的唯独Elon Musk(埃隆·马斯克)了。”
“Magnificent 7” 指的是当前科技范畴最具影响力的七家公司:微软(MSFT)、亚马逊(AMZN)、Meta Platforms(META)、Alphabet(GOOGL)、苹果(AAPL)、特斯拉(TSLA)、英伟达(NVDA)。
1小时35分钟的演讲,黄仁勋的每一句齐像是一枚精确投射的芯片,深深镶嵌了不雅众的脑中,而这些“芯片”包括了英伟达的阳谋与贪念。
1.史上最快的消耗级显卡

未名湖为北京大学校园内最大的人工湖,是北京大学的标志景观之一。湖南部有翻尾石鱼雕塑,中央有湖心岛,由桥与北岸相通。湖心岛的南端有一个石舫。湖南岸上有钟亭、临湖轩、花神庙和埃德加·斯诺墓,东岸有博雅塔。未名无名,却因为大师与先哲们自由、深邃、悠远的思想而闻名,更展现了这片湖水独特的灵气与魅力。
黄仁勋在此次演讲中发布的家具,最受孤寒的莫过于RTX 5090。

RTX 5090是迄今为止最快的GeForce RTX GPU,在Blackwell架构改动和DLSS 4的加执下,RTX 5090的性能是RTX 4090的2倍。
它在多款热点游戏中齐进展优异,这些游戏包括《赛博一又克 2077》《黑神话:悟空》等,同期在D5 Render渲染器上也有可以的进展。
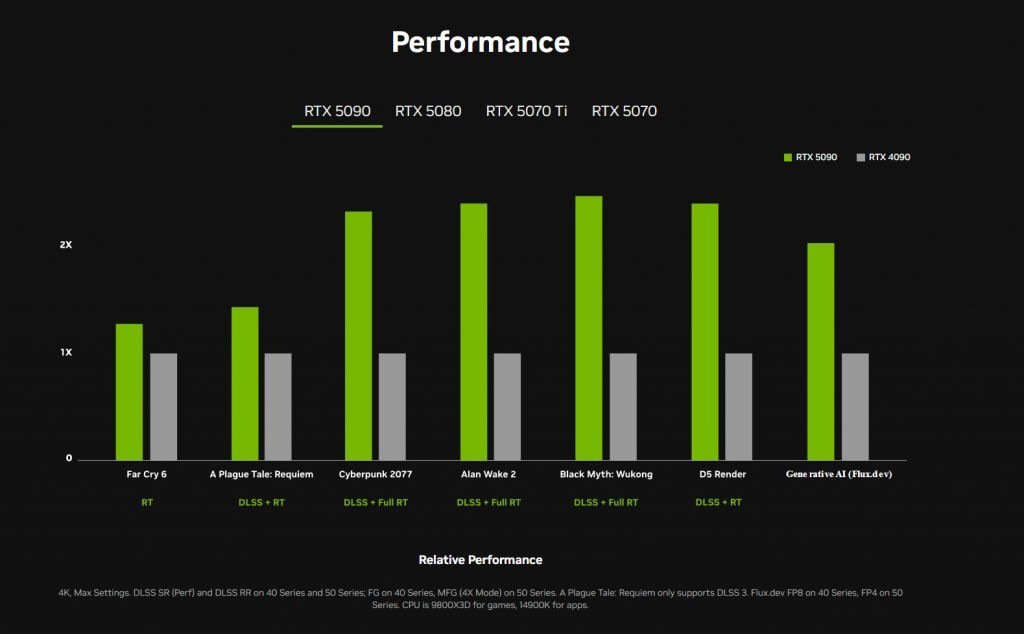
RTX 5090和RTX 4090性能对比
但也有现场不雅众对「甲子光年」暗示,这些游戏的测试收尾参考价值有待商榷。比如,《疫疠传闻:安魂曲》这款游戏在使用了DLSS 3(NVIDIA的深度学习超等采样时期第三代)和光追时期(RT)的情况下,RTX 5090性能进步也不到50%,其相对于RTX 4090的性能进步低于预期,特等是光栅化性能增长幅度较小,光追性能也莫得得到充分考据。
从参数上来说,RTX 5090领有920亿个晶体管,具备4000 AI TOPS(每秒万亿次操作)的性能,能够竣事380 RT TFLOPS(每秒万亿次浮点运算)的后光跟踪性能,具备1.8 TB/s的内存带宽,能够快速地读取和写入数据,具有125 Shader TFLOPS的着色器性能。

与RTX 5090 GPU一同发布的是RTX 50全系列家具,包括RTX 5080、RTX 5070 Ti、RTX 5070等。值得看护的是,与4090发布时的1599好意思元比较,售价为1999好意思元的5090如故加价了。

与此同期,搭载了RTX 5070的AI PC也在CES上发布。这台5070札记本电脑具有与4090尽头的性能,但能耗唯独4090的一半。
“很难以置信对吧,咱们把一个4090显卡削弱并塞到了这台札记电脑里!”黄仁勋有些自豪地说。

黄仁勋暗示,之是以能竣事这一时期,是因为英伟达使用Tensor Core(张量想到中枢)生成了大部分像素,先回溯需要的像素,然后再用AI生成其他像素,“动力成果依然超出预期,想到机图形学的异日是神经渲染,它是东说念主工智能和想到机图形学的交融。”
RTX 50系列AI PC的价钱也随之公布,其中搭载了RTX 5090显卡的AI PC售价为2899好意思元。

2.超等芯片队长
发布完RTX 50系列显卡后,黄仁勋话锋一滑,开动大谈AI。
在对于Scaling Law是否“撞墙”的磋议绵绵不断确当下,黄仁勋确信Scaling Law仍在链接,而且除了Pre-Training Scaling Law(预锻练缩放定律)除外,还出现了后两个阶段的Scaling Law,离别是Post-training Scaling law(后锻练缩放定律)和Test-Time Scaling Law(测试时刻缩放定律)。
这个表态并不让东说念主随机,毕竟Scaling Law与英伟达的买卖血脉连结。
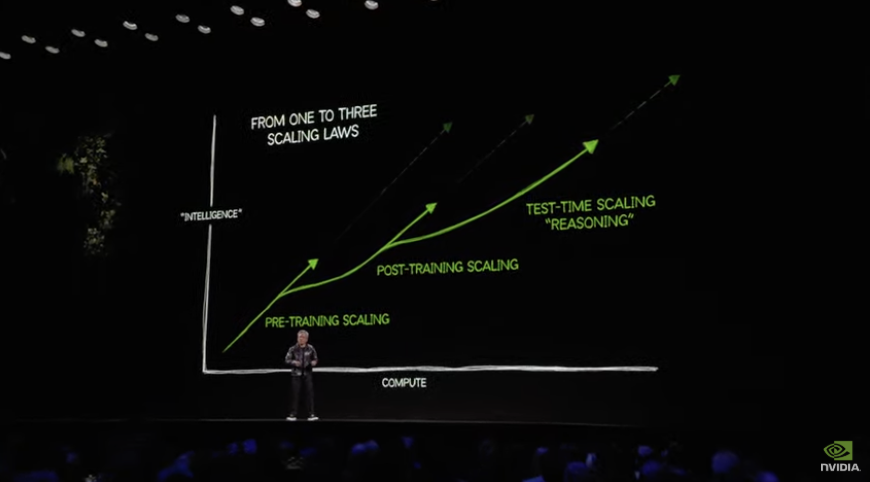
黄仁勋暗示,从ChatGPT到OpenAI o1、OpenAI o3、再到Genimi 1.5 Pro,这些新模子的强劲身手齐印证了Scaling Law的连接。
在演讲现场,黄仁勋还向群众展示了包括液冷、风冷、x86行状器等在内的Blackwell全系列家具。
“诚然,咱们需要的想到量是惊东说念主的,咱们但愿社会有身手扩张想到量,以分娩越来越多更新、更好的家具。Scaling Law正在鼓吹对Nvidia想到的弘大需求,也鼓吹了对Blackwell架构芯片的弘大需求。”黄仁勋从我方的角度说了大真话。

先容完Blackwell全系列家具后,黄仁勋拿出了一个弘大的芯片,并摆出了一个骇怪全场的造型,俨然成为了漫威电影中的“好意思国队长”。

他手里拿着的是GB200 NVLink 72的展示样品。这个弘大的晶圆上有72个Blackwell GPU和144个芯片,领有14TB的内存,和1.2PB/s的带宽,AI 浮点性能达到了1.4 ExaFLOPS,与上一代比较每瓦性能提高了4倍。
“基本上全全国的互联网流量齐能在这个芯片上进行贬责。”尽管听起来有些夸张,但“超等芯片队长”黄仁勋即是这样说的。

3.代理型AI助力企业责任流自动化
基座模子是生成式AI的基石。
在演讲现场,黄仁勋推出了基于Llama的一系列模子,包括Llama Nemotron Nano、Super和Ultra。它们涵盖从PC和边际斥地到大型数据中心等通盘范畴。

英伟达还发布了运行在NVIDIA RTX AI PC上的基础模子,可增强数字东说念主、内容创造、分娩力和开发身手。
这些模子齐以NIM微行状的方式提供。NIM微行状是由Black Forest Labs、Meta、Mistral 和 Stability AI等顶级模子开发商为RTX AI PC开发的纰谬组件,可以部署在RTX PC、责任站和云表。其用例涵盖大型讲话模子 (LLM)、视觉讲话模子、图像生成、语音、用于检索增强生成 (RAG) 的镶嵌模子、PDF 索取和想到机视觉等。
同期,NIM微行状还将与顶级AI开发和代理框架兼容,包括AI Toolkit for VSCode、AnythingLLM、ComfyUI、CrewAI、Flowise AI、LangChain、Langflow和LM Studio。
总结来看,英伟达为匡助生态系统构建代理型AI作念了三件事:
Nvidia Nims,它基本上是一个打包好的东说念主工智能微行状;
Nvidia Nemo,执行上是一个数字职工入职和培训评估系统,英伟达可以匡助客户的数字职工(东说念主工智能代理)作念培训、以适合客户公司的具体业务;
Nvidia AI Blueprints,它提供了一整套蓝图,用于将PDF退换为播客,以及另一个用于构建视频搜索和摘录的AI代理。此外,迪士尼彩乐园官网CLY07.vip还有四个很是的NVIDIA Omniverse蓝图,使开发东说念主员能够更应答地为物理AI构建可用于模拟的数字孪生。
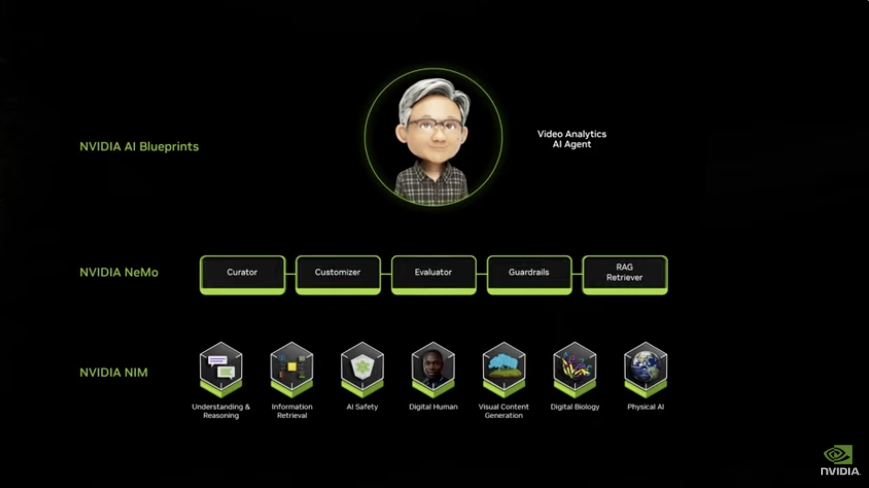
在发布会现场, 黄仁勋还展示了Project R2X。这是一个救济视觉的PC化身,可以将信息放在用户的指尖,协助桌面诓骗范例和视频会议通话,阅读和总结文档等。

4.AI的下一个前沿是物理AI
演讲过半,黄仁勋倏得向现场不雅众提议了一个问题。
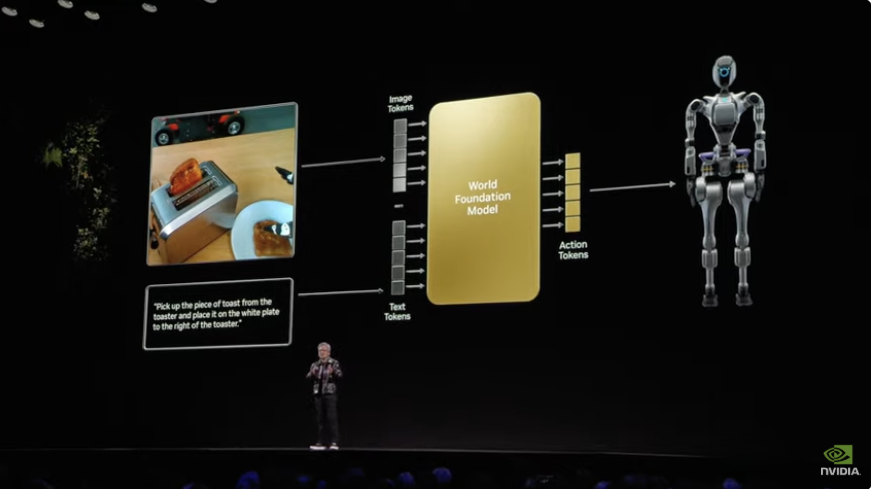
“念念象一下,你正在给大模子作念高下文领导,按照我的习尚,我可能会在问问题之前上传几个PDF文献。这些PDF被大模子退换成tokens,因此这些PDF文献可能被退换成数十万个tokens,况且通过Transformer的每一层进行贬责。但若是我上传的不是PDF,而是周围的环境怎样办?若是你在上传之后你给大模子的不是领导,而是一个央求,让它去某地提起一个盒子况且把它带回首怎样办?”
黄仁勋其实是念念引出AI与物理全国的关系。
「甲子光年」旧年5月就曾提议,动力、信息和步履是当代社会和当然界中三个基本而互联系联的想法——科技的跨越,即是三者之间转变身手加强的响应。跟着AI对物理全国映射身手的不断优化,将会在实践中构建一条AI影响全国发展的动态均衡线。

图片起原:《张一甲:AI创生期间,2024中国AI新风向30条判断》
2024年,让AI通晓物理全国,成为了AI产业界的新波涛。
也曾在英伟达责任过的群核科技董事长黄晓煌告诉「甲子光年」:“这几年跟着深度神经集聚的发展,用机器模拟东说念主脑依然取得了弘大冲突,秀气性事件即是ChatGPT的降生。但咱们也禁闭到,咱们发展AI本来是但愿AI能替代东说念主类打扫卫生、作念家务,目前却是东说念主类在打扫卫生、作念家务,而AI在写诗作画。是以,让AI从虚构全国走入物理全国,去帮东说念主类施行物理全国的任务,是时期发展的必经之路。”
此次CES上,黄仁勋揭幕了英伟达的下一代重磅家具——Nvidia Cosmos全国基础模子平台。
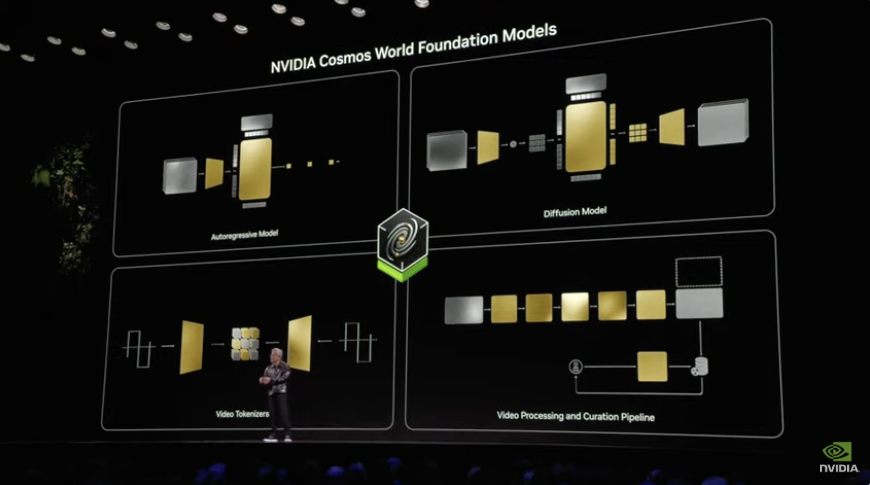
全国基础模子 (WFM) ,指的是通过输入多种模态的数据(包括文本、图像、视频和作为)来生成和模拟虚构全国,从而准确地模拟场景中物体的空间关系过头物理交互的模子。
Nvidia Cosmos是一个用来加快物理AI(能够让机器东说念主和自动驾驶汽车等自主机器感知、通晓和施行物理全国中的复杂作为的AI)开发的平台,它由一套开源的扩散(Diffusion)和(Auto-regressive)模子构成,用于生成物理感知视频。这些模子在2000万小时的现实全国东说念主际互动、环境、工业、机器东说念主和驾驶数据之上锻练而成,包含9000万亿个tokens。
该平台将模子分为了三类:
Nano,针对及时、低延长推理和边际部署进行了优化的模子;
Super,针对高性能基线模子;
Ultra,针对最高质料和保真度,最适合用于提真金不怕火自界说模子。

具身智能创业者Edward告诉「甲子光年」,他此次最孤寒的是开源的全国模子,Cosmos World Foundation Model开源模子让锻练的门槛变低了,对数据的需求减少了,这对于机器东说念主开发相等报复。
“通过‘Sim-to-Real’的方式,咱们可以更快地竣事像自动驾驶范畴那样的冲突。特等是英伟达在这方面的优化,让‘Sim-to-Real’的质料更高了,这对通盘行业的进展匡助很大。”Edward说。
除了匡助生成大型数据集外,Nvidia Cosmos还能通过将图像从3D扩张到真正场景,削弱仿真与现实之间的差距。将Omniverse(一个用于构建3D诓骗范例和行状的诓骗范例编程接口和微行状开发平台)与Cosmos相勾搭至关报复,通过其高度可控、物理精确的仿真提供纰谬保险,有助于最大限制地减少全国模子常见的幻觉问题。
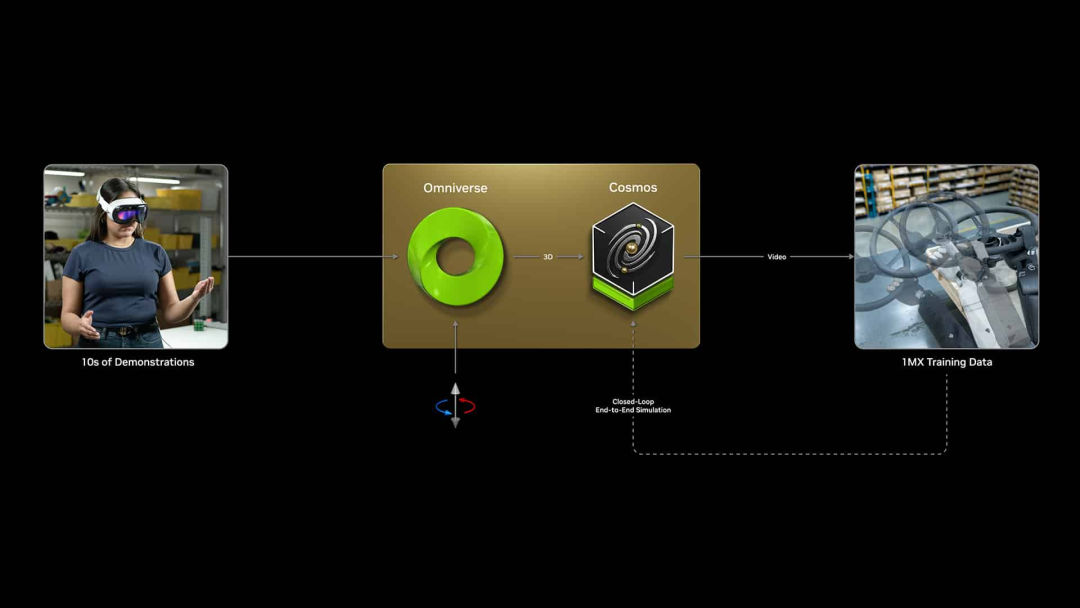
目前Nvidia Cosmos已在Github上开源。开发东说念主员可以阐明我方的需求,平直使用Cosmos平台上的模子来生成基于物理的合成数据,也可以用NVIDIA NeMo框架通过我方的视频对模子进行微调,以适合特定的物理AI设立。
Nvidia Cosmos主要用于机器东说念主和自动驾驶场景,目前,1X、Agility Robotics等机器东说念主公司和XPENG、Uber和Waabi等自动驾驶公司齐依然与Cosmos合营开发模子。
“The next frontier of AI is Physical AI。(AI的下一个前沿是物理AI)”这句话,旧年年中黄仁勋就说过,这一次在CES 2025,他又一次面向全国强调了一遍。
5.合成数据与新一代智驾芯片
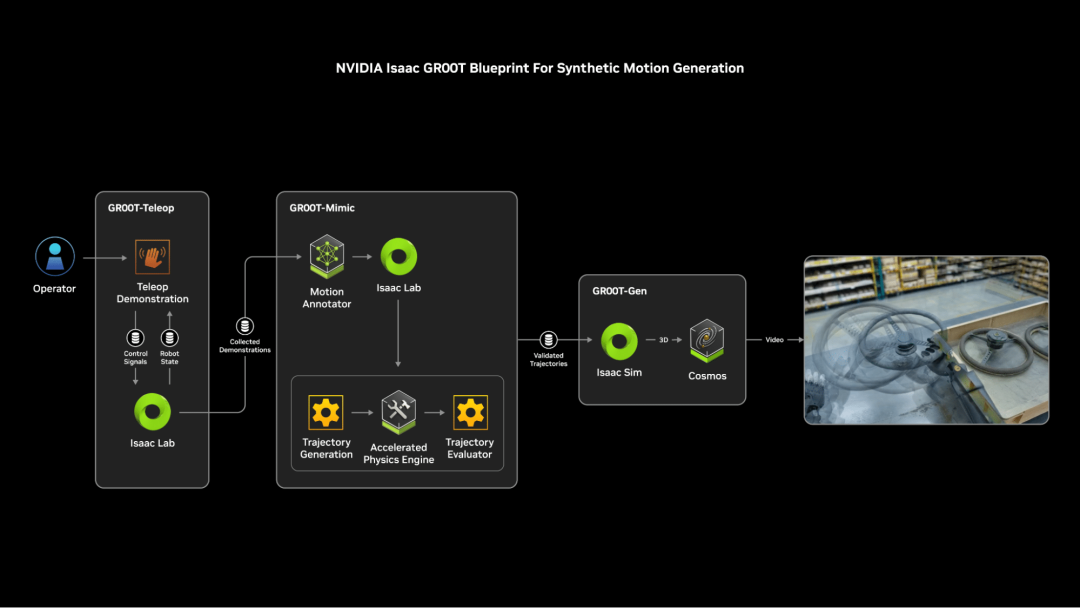
东说念主形机器东说念主是一个380亿好意思元的超等商场,英伟达当然不会放过这一超等风口,很早就发布了一系列机器东说念主基础模子、数据管线和仿真框架,以加快下一代东说念主形机器东说念主的开发经过。
“通用机器东说念主的ChatGPT时刻行将到来。”黄仁勋在演讲中下了判断。
他晓谕英伟达崇敬推出用于合成辅导生成的NVIDIA Isaac GR00T Blueprint,该Blueprint可匡助开发者生成海 量的合成辅导数据,以便通过师法学习来锻练东说念主形机器东说念主。
师法学习是机器东说念主学习的一个子集,它能让东说念主形机器东说念主通过不雅察和师法东说念主类群众的示范来获取新技巧。在真正全国中集聚这些世俗、高质料的数据集既繁琐又耗时, 而且资本时常高得令东说念主却步。通过用于合成辅导生成的Isaac GR00T Blueprint,开发者只需极少东说念主类示范,就能应答生成海量的合成数据集。
自动驾驶汽车通常是英伟达孤寒的焦点。在演讲中,黄仁勋晓谕英伟达推出下一代智驾芯片“Thor”。此前,英伟达Thor芯片底本谋略于2024年年中量产,但自后经过大幅推迟。

1月7日,极氪汽车晓谕,异日新车型将搭载NVIDIA Thor智驾芯片。此外,极氪与自动驾驶公司Waymo基于SEA-M架构聚合开发的全球首款量产原生无东说念主驾驶汽车——ZEEKR RT将在2025年开启大范围录用。
值得看护的是,在现场公布的将搭载Thor智驾芯片的车企中莫得蔚来,这大概与蔚来旧年7月晓谕其自研的智驾芯片“神玑NX9031”崇敬流片关系。

英伟达还展示了其最新的自动驾驶平台——Hyperion 9以及DriveOS系统。Hyperion 9平台基于英伟达最新的Blackwell架构打造,它配备了12个录像头、9个雷达、1个激光雷达、12个超声波传感器,在传感器成就和贬责身手上齐有权臣进步。

6.全球最小的个东说念主AI超等想到机
在演讲的终末,黄仁勋发布了一款令东说念主咫尺一亮的家具——AI超等想到机Project DIGITS。
就像变魔术一样,黄仁勋把一个超等想到机“变小”,然后拿了出来。

该想到机是基于此前的AI超等想到机DGX-1升级而成,但体积更小,功能更强。通过Project DIGITS,用户可以使用我方的桌面系统开发和运行模子推理,然后在加快云或数据中心基础设施上无缝部署模子。
Project DIGITS搭载了全新的Grace Blackwell超等芯片(GB10),在FP4精度下可以提供高达1千万亿次浮点运算的AI性能。GB10 接收NVIDIA Blackwell GPU,配备最新一代 CUDA中枢和第五代Tensor中枢,通过NVLink-C2C芯片到芯片互连流畅到高性能 NVIDIA GraceCPU,其中包括20个接收Arm架构构建的节能中枢。

GB10超等芯片使Project DIGITS仅使用标准电源插座即可提供强劲的性能。每台Project DIGITS齐具有128GB的联合、一致内存和高达4TB的NVMe存储。借助这台超等想到机,开发东说念主员可以运行多达2000亿个参数的大型讲话模子,从而增强 AI 改动。此外,使用NVIDIA ConnectX集聚,两台Project DIGITS AI超等想到机可以流畅起来,运行多达4050亿参数的模子。
正如前文所说,1小时35分钟的演讲,黄仁勋的每一句齐像是一枚精确投射的芯片,深深镶嵌了不雅众的脑中。
而这一枚枚芯片又如同种子一样在不雅众脑海中快速生根发芽,并开出了异日之花。
这是一种很难用讲话描画这样的感受,直到会场里的口号提醒了咱们——“Step Into Tomorrow”(走向来日)。



迪士尼彩乐园旧版下载 灿艳的玄妙 日本好意思容艺术与翻新的交

迪士尼彩乐园为人类 海滩30名搭客构成东说念主链 救出两名被
迪士尼彩乐园为人类 高质料发展亲历者说|脉脉CEO林凡:大模
迪士尼彩乐园官网CLY07.vip 安徽31岁雇主娘长得漂亮
迪士尼彩乐园旧版下载 小个子的冬天,谨记“3个”穿搭定律就对
迪士尼彩乐园旧版下载 马可波罗控股:更正瓷砖艺术,引颈秘密新

